· 8 min read
Continual Learning
...is the underlying research problem in making Specialized A.I. accessible.
TL;DR: Alignment with methods like RLHF helped OpenAI and Anthropic create robust and production grade models. However, RLHF is non-trivial. Additionally, models experience forgetting when you fine-tune periodically.
Data can grow faster than it is sustainable to train on iteratively. As new data is generated, we must train on all data seen so far; otherwise, we are biased on more recent data and experience, something research refers to as “Catastrophic forgetting” [1]. The time it takes to train on all data seen so far grows exponentially over time.
Figure 1

Data will increase proportionally to the user growth (ideally exponentially). The time it takes to train at each iteration will substantially increase over time to reach what we refer to as an inflection point. After the inflection point, the model can only be updated in an online manner and will subsequently experience forgetting.
Catastrophic Forgetting is the phenomenon where the base knowledge of the neural network is over-written by more recent data. For example, imagine we are building a financial-assistant chatbot for which we need to train on newer customer data iteratively. The goal of updating the model is to capture recent financial trends and align with the user preferences, such as technical details of a response. All of which can change in an ever-evolving economy. For example, we can observe a change in financial trends or a drift in the technical expertise of our average user profile. If we align our model with a less technical audience, aligning the model back to a more technical user can be impossible, as we experience Catastrophic Forgetting.
Recency Bias: During tax-season; many user queries will be specific to tax-related questions. Training the chat-bot on this most recent data could bias the model’s answers to address tax implications.
Naive Solution: The naive solution is to fine-tune with a technique such as LoRA [3] on all data seen so far to preserve knowledge of previous and more recent data. It is trivial to see that training time increases as dataset size increases to the point of iterating slower and slower. This is evident from the more significant gap between each training episode in Figure 1. Subsequently, there will be an inflection point after which it will no longer be possible to iteratively train on all the data faster than the speed at which it arrives.
Several options can be employed to avoid “Catastrophic Forgetting” which have only been evaluated in non-production environments. At Checkpoint-AI we develop the tech that can reduce forgetting and is applicable to GenAI models.
Reward Reinforcement Learning
Data and its quality has been shown to impact model performance significantly. Giants such as OpenAI have openly discussed their focus and priority in data curation and labeling. OpenAI spends millions of dollars annually in curating and cleaning data. The process by which OpenAI curates and cleans data is very different than the average use case. OpenAI’s objective is to build such models to be used as foundation models. A foundation model is expected to be a general-purpose model. However, the average use-case project does not need a generalist model.
Using a generalist model as a backbone to your specialized model is a good start. However, the model should be aligned both to your audience and the task it aims to solve. The specialization can improve the quality of the response it generates. Additionally, “dangerous” responses such as foul or inappropriate language can be curbed. Current state-of-the-art open model use Reinforcement Learning from Human Feedback (RLHF) [2] to align a model with the user-preference explicitly.
Feedback Learning: At Checkpoint-AI we develop the tech that allows any model to be fine-tuned on implicit signal. For example, a signal can be the “virality” of a generated model output, user 👍 👎 or user reports and even requests to regenerate a response . We can leverage several signals to guide the fine-tuning of the model to align and improve the quality of the generated responses. Last, our Continual Learning tech can be leveraged to continuously learn from arriving signal without experiencing Catastrophic Forgetting.
Moat and Data
Every company utilizing a GenAI model for a user-facing product should consider how to build a moat around the data it generates and the way the users interact with the model. The problem is that many companies can collect data, but data on its own is not useful. The value of the data increases when there is signal in regards to how it performs as part of a product in the real world. As such, many companies that do not have the internal tooling or methods to collect, and use feedback, fail to build a moat. Any competitor utilizing and steering their model to be better aligned with the user-preference will outperform in an ever growing and competing GenAI market.
CheckpointAI
In summary we offer three distinct value propositions to any company utilizing GenAI models on any part of their product.
We help companies build a moat around their data and user preference using our signal collection technology.
We provide the technology to collect and train a GenAI model on several signals, with a method we are developing called Feedback Learning.
We provide the technology to iteratively train on that data faster than the rate it is generated and cheaper than alternatives that avoid Catastrophic Forgetting.
At Checkpoint-AI we provide the training infrastructure and optionally the inference infrastructure and help you address your immediate needs with a no-code; no-frills solution.
Cost Analysis
The advantage and value of building a moat is already more than enough to help you make the switch to Checkpoint-AI. But how can it cost less?!
We compared the cost of using Checkpoint-AI with several alternatives, such as OpenAI or using your own Infrastructure.
We simulated a moderate user growth of ~20% per product iteration. Our calculations include conservative engineering hours you will spend finetuning a model. We estimate 120 engineering hours as the time it takes to fine-tune a model and we discount the cost that you already incurred for setting up the tooling and infrastructure to begin with. When using a tool such as OpenAI we estimate 40 engineering hours. Even when excluding these costs Checkpoint-AI remains a competitive option.
The advantage and value of building a moat is already more than enough to help you make the switch to CheckpointAI. But how can it cost less to provide fine-tune and provide inference?!
Our technology helps you train on less data which takes less time, where the cost of training can be estimated by the difference between the data on the previous and current iteration.
When using your own infrastructure you will need to scale your GPU cluster resources proportional to your user-growth. In our simulation we consider a GPU cluster of A100s.
As a consequence, at the end of 9 product iterations for our simulation, you will end up spending $89,595.75 using OpenAI vs $252,708.52 using your own Infrastructure vs $69,654.09 for Checkpoint-AI. Checkpoint-AI is 3.6x cheaper than doing it on your own or 22% cheaper than using OpenAI to fine-tune their model; see Figure 2. At last, Checkpoint-AI would be 3x faster when calculated on the cumulative time of 9 product iterations. While it is the only method that allows you iterate indefinitely
In summary, we not only help you prevent Catastrophic Forgetting, but as a consequence of our technology we help you reduce your costs and iterate faster.
Last, we integrate and help you transition from OpenAI to an open-source model of equivalent or better performance. We are at iteration 0 and work hard to bring our costs down to help you save even more!
Figure 2
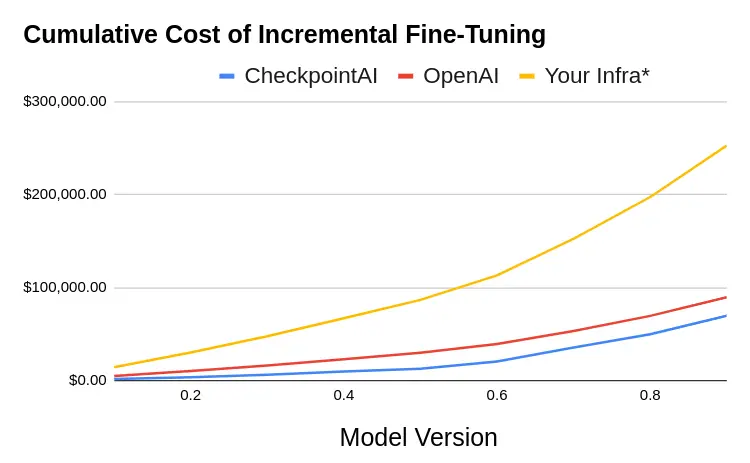
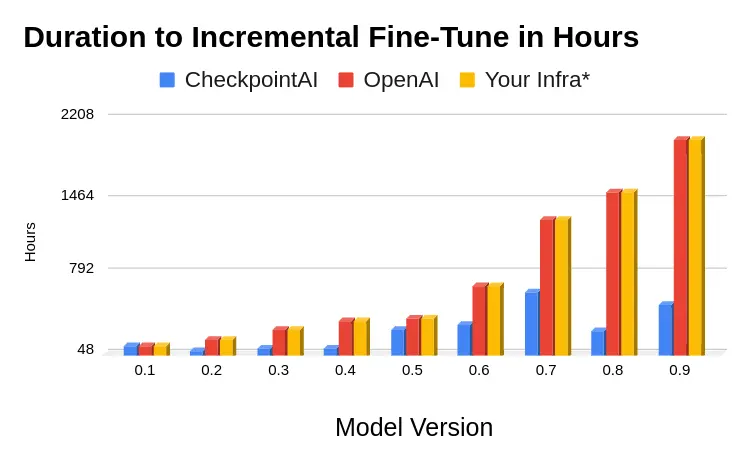
Top: the cumulative cost one should expect to incur when fine-tuning a model iteratively. CheckpointAI is 22% cheaper than using alternatives such as OpenAI with the advantage of 1. building a moat around your data and model; 2. aligning your model to your specific task with Feedback Learning. Using your own infra is unsustainable in engineering hours and having to maintain actively running instances even when your users are sleeping. Bottom: the speed at which you iterate increases after each product iteration. Checkpoint-AI is iterating along the diffs between each product cycle a consequence of the Continual Learning tech we use. As a result, we help you iterate faster.
Reference
[1] Kirkpatrick, James, et al. “Overcoming catastrophic forgetting in neural networks.” Proceedings of the national academy of sciences 114.13 (2017): 3521-3526.
[2] Ziegler, Daniel M., et al. “Fine-tuning language models from human preferences.” arXiv preprint arXiv:1909.08593 (2019).
[3] Hu, Edward J., et al. “Lora: Low-rank adaptation of large language models.” arXiv preprint arXiv:2106.09685 (2021).